

The significance of organizational decisions on engineering efficiency


The systems that people work in and the interactions with people may account for 90 or 95 percent of performance.
- W. Edwards Deming
Regardless of where you look in life, there are systems that are managing just about everything. Some of those systems have been well thought out while others just seem to happen naturally. Everything from standing in line at the grocery store, getting your dry cleaning done, or how software is developed.
In a lot of these areas, its easy to see the waste and friction but is a bit weird how we miss so much when it comes to the way we do things. Some of these can be annoying, such as waiting for 20 minutes in the check out line. In the software delivery lifecycle, that 20 minute wait might have hundreds of times a month and cost thousands of hours of wait time.
In the SDLC, how is it that we see some things but completely miss others? I think a lot of it has to do with how organizations are setup and the way they interact with one another.
If you are really interested in improving engineering efficiencies, develop productivity, or developer experience, then you will need to understand these four key areas, their interaction patterns, and unique challenges.

In this article, we are going to dig some examples Organizational waste and friction and how to think about resolving them. Make sure to subscribe so you can get the follow up articles where we break down the rest.
Organization / Org. Unit
Decisions made at this level can have significant impact across every aspect of software delivery, though they don’t seem to be scrutinized as much as you might expect.
A great examples of this could be agile methodologies, funding and prioritization, or security processes. These are the biggest rocks to move but can have the biggest impact and should be the focus of senior leadership.
Lets dig into a few examples and the impact it might have on an organizations overall efficiency.
Using the wrong planning methodology

I absolutely hate this framework and just about everything that it stands for, if I am going to be honest. Lets look at the four key values in the agile manifesto.
Individuals and interactions over processes and tools.
Working software over comprehensive documentation.
Customer collaboration over contract negotiation.
Responding to change over following a plan.
SAFe basically breaks every one of these before lunch on the first day… but this is on a post about bashing SAFe but its impact on an organization.
At its core, SAFe is all about planning, process, and improvement which sounds great on paper but how does it actually work out in the real world? Ask anyone who has ever gone through Program Increment (PI) planning… and they will tell you all about it.
So PI planning is a 2 day (at least) event with this agenda.

“Facilitated by the Release Train Engineer (RTE), this event includes all members of the ART and occurs within the Innovation and Planning (IP) Iteration.”
SAFe
Oh yeah… and this whole show is supposed to happen during the last sprint of the quarter.

“Holding the event during the IP iteration avoids affecting the scheduling or capacity of other iterations in the PI.”
SAFe
So what really happens with this 6th sprint? It becomes the buffer for all of the bad estimates that where made (based on very little evidence) from the last PI planning. Instead of this being an “improvement sprint” it becomes a mad house of rushing to “not ruin the planning for the next PI”.
This is quite literally the exact opposite of really great practices like continuous discovery and dual track development. Ill cover these in another article.
But lets look at the waste and friction in this process.
We expect all team members to take two weeks a quarter to do “planning”
There is a ton of overhead in this system. Someone tell me what a Release Train Engineer actually is other than a program manager???
There is an expectation that we actually know how to estimate the work that is being planned
That we can actually know what the needs of the business are for the next quarter and can plan appropriately
In a perfect world these things would all just work out and you go an execute the PI plan and everything is happy… but we all know this is never going to be the case.
So what happens when things go awry?
So if business priorities change or new events come up, it turns into crisis mode because you have to keep the “plan” intact. This has a ripple affect across the entire organization.
You need to change all of the pretty sprints that were built into Jira (or whatever tool)
You need to check on all of the inter-dependencies that might be affected
You need to get new “estimates” on the work to be added into “the plan”
There will need to be some bartering or bargaining with other stakeholders on what get removed from “the plan”
The current sprint velocity is now impacted because of the need to do the estimates… so now stories need to be moved to a new sprint.
It reminds me a lot of this skit.
I think you get my point… it can turn into chaos very quickly. This process was supposed to provide clarity and predictability to the process and all it has done is cause more problems.
From a developers prospective, how do you think this makes them feel? A good amount of software developers just want to come in and do the job they were hired to do… write software… not whatever this circus is.
There is all of this organizational friction and waste coming from this process, so what happens when times get a little difficult or there are tight deadlines to hit? There is immense pressure put onto the development teams to “deliver faster”.
So they tend to cut corners and make poor architectural decisions which just adds to the technical debt making it harder to deliver in the future.
Does this sit well with a lot of the developer community? No.. no it doesn’t.
This is when a lot of people start to vote with their feet and leave an organization or become apathetic in general. Queue the doom spiral of poor output, quality, and predictability.
Better call in the SAFe consultants… because you must just be doing it wrong… Don’t worry, for another 500k they can help you improve your planning. :-)
The question I would have here… is how much time and energy is wasted here? How many hours are lost? And for what? A plan that doesn’t provide much more than hopes and dreams?
There are a ton of better ways to get business planning done but there is no silver bullet. It takes good leadership, continuous discovery, and understanding the outcomes you are trying to drive towards.
Organizational Silos - Ticketing Systems
Lets say I am the tech lead on a new team that needs to create a set of new services. I will need a few basic things to get started.
Git repo
Cloud environment
I will need to get these provisioned in one way or another. Back in the day, one might just send an email or reach out to someone on a team to get them to create the stuff they need. This worked in a lot of ways but was hard to scale and even harder to track.
Bring on the ticketing system! They will provide tracking and data around what is needed make sure the requests have all of the necessary information.
The theory behind this one was solid… in 2003… but times have changes significantly and so should you.
While this did help with a lot of issues, there is still a ton of waste in this process. There are two humans involved so we can safely assume that there will be trouble somewhere.
The Git repo is easy enough but the cloud environment can become a whole lot trickier… and it all comes down to my good friend, governance.
Soooo, what kind of a cloud environment do you need? Are you going to be using K8? Serverless? Is it a front end or just a back end? What about networking? Oh yeah, who actually approves what gets provisioned?
I recently worked with a client who had this exact situation. They had over 100 questions on their “cloud intake form” and there was a “cloud architecture review board” that met every Tuesday.
If by some miracle you could actually figure out how to get this form filled out you would have to wait at least a minimum of a week to get it reviewed. Then if another miracle happens, you might get your provisioning done within another week. This is because of the ticket wait times for the cloud team to actually do the provisioning of the infrastructure.
In reality, this takes much, much longer than this. On average, the wait time for someone to get through this process was between 6-8 weeks. In total, the time it took to get something new into production was between 93 and 189 days.
Are there better ways to do this in modern software engineering.. yes, yes there is.
This is really the genesis of things like platform engineering and governance at the point of change come it. These topics are far outside of the scope of this article but will definitely write about them in the future or talk about them on the podcast.
The compounding factors
Each of these two problems sound nasty enough but lets consider how they interplay with one another.
If you are trying to plan out for an entire quarter or more (via SAFe) and you have a cloud intake process that takes 93-189 days to complete. What could possibly go wrong?
This means you need to try and guess (sorry… i mean plan) what is going to happen even further out into the future making your organization more rigid and less agile overall. This adds to the overall doom loop and the continuation of the overall mess that is continuing to happen.
So what can you do about it
Planning and running an organization is hard, there are no doubts about that. It takes a strong leader to be able to take a step back, use a clear mind, and map out the experiences that are happening through out the organization.
To me, this really is a cultural problem that is set from the top. It reminds me of a quote I have hanging on the wall in my office.
Have a mind that is open everything and attached to nothing
Its so easy to get caught up in the “this is how we do things” mantra and never reconsider how things might be done better especially in the era of cost savings and optimization.
Very rarely do I find problems that the vast majority of an organization doesn’t already know about. The problems I do find are the ones that people wont talk about even consider.
This really leads into the first thing you can do to help with some of this chaos.
Talk to and listen to your organization
There are a lot of ways you can get this done from surveys, Q&A sessions, townhalls, or talking to your leaders. The one critical part is that there has to be a culture where its ok to say that this thing is broken or needs to be changes.

Set up foundation of data to build metrics and help make decisions
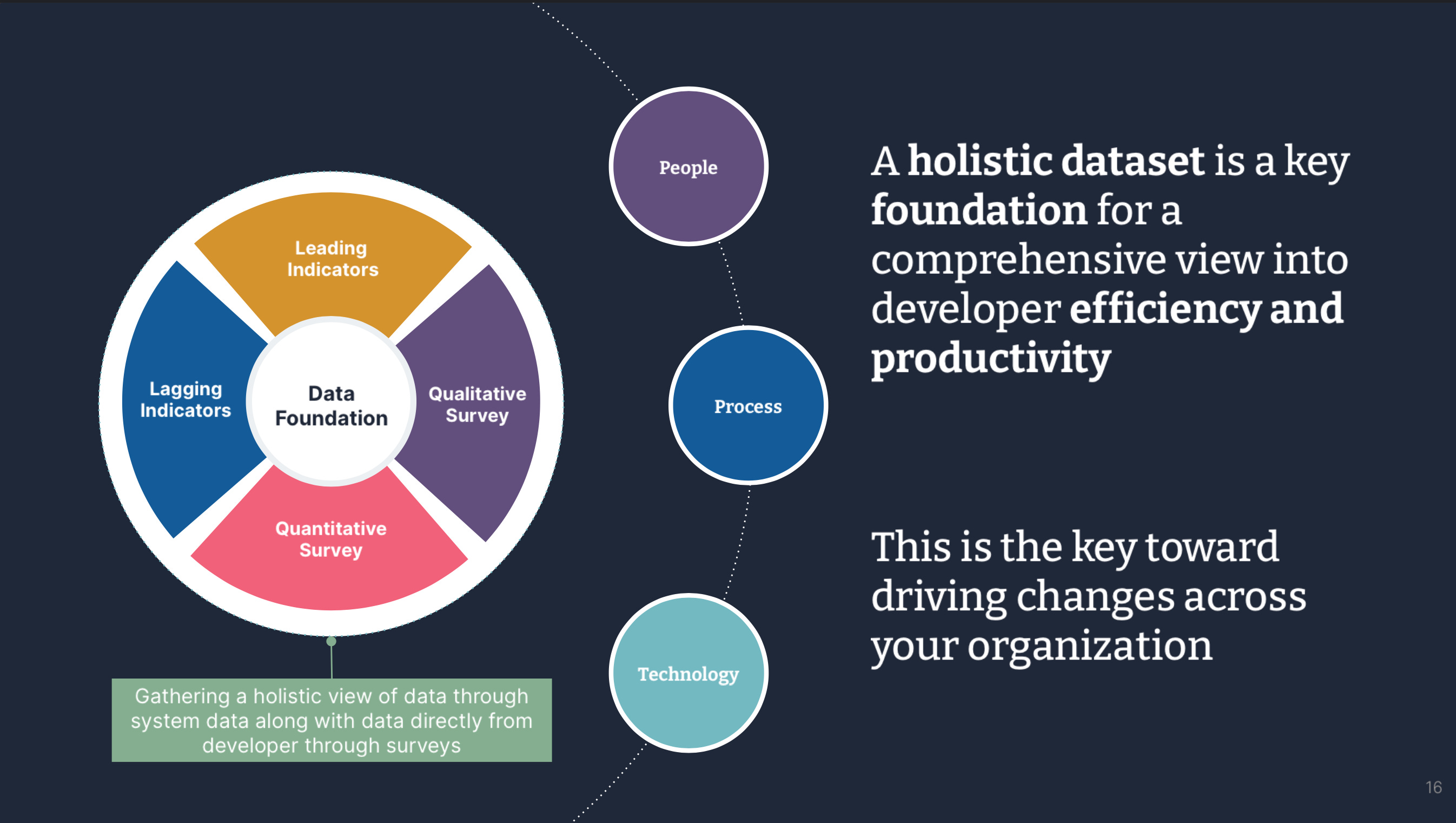
Getting this foundation setup is the key towards making solid decisions. It is what you need to build out leading and lagging metrics and should include system data along with survey results.
With this data you can easily identify problematic areas inside of the organization along with the metrics to show its overall impact.
Have a team focused on continuous improvement
Building your data foundation and identifying metrics is only part of the problem, now you have to figure out how to actually make an impact. This is where you need a team to help identify the hotspots, strategize solutions, value modeling, and building a business case.
Conclusion
These are key focus areas that help organizations be more efficient. Unfortunately, there is no silver bullet that makes all of these problems go away… regardless of what some consultant told you. :-)